Point SA
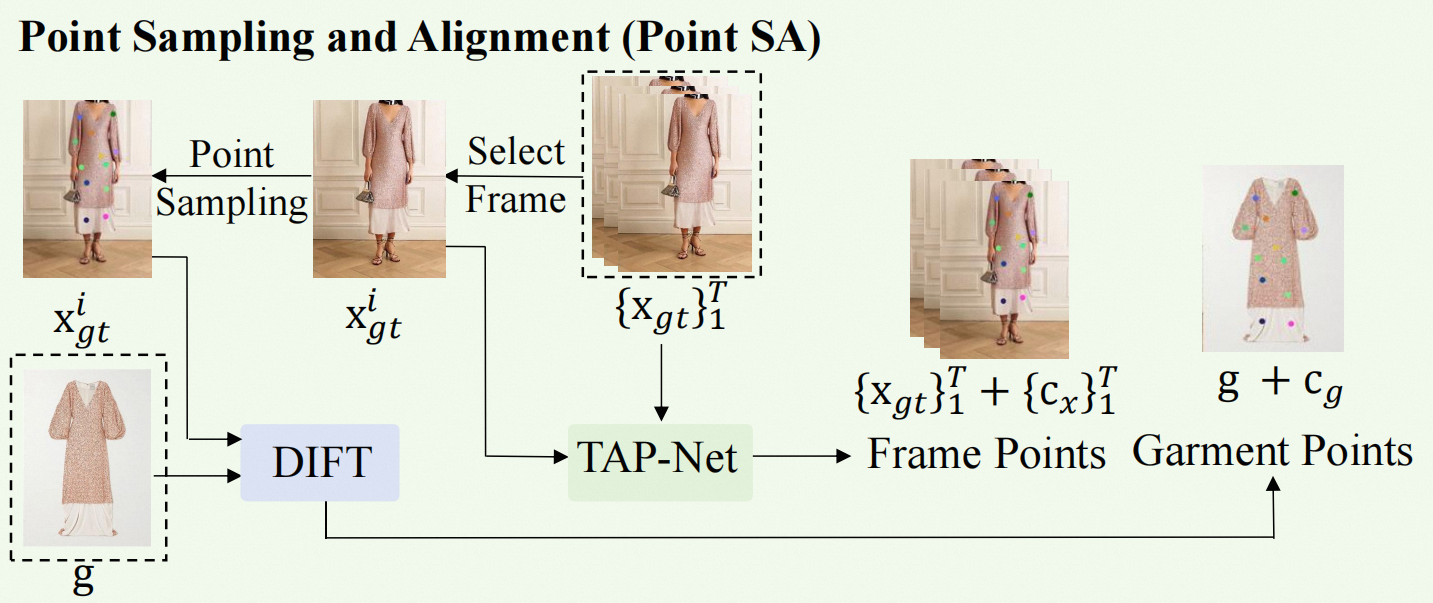
The pipeline of the construction for point alignments between video frames and garment images.
Video Virtual Try-on aims to seamlessly transfer a reference garment onto a target person in a video while preserving both visual fidelity and temporal coherence. Existing methods typically rely on inpainting masks to define the try-on area, enabling accurate garment transfer for simple scenes (e.g., in-shop videos). However, these mask-based approaches struggle with complex real-world scenarios, as overly large and inconsistent masks often destroy spatial-temporal information, leading to distorted results. Mask-free methods alleviate this issue but face challenges in accurately determining the try-on area, especially for videos with dynamic body movements. To address these limitations, we propose PEMF-VTO, a novel Point-Enhanced Mask-Free Video Virtual Try-On framework that leverages sparse point alignments to explicitly guide garment transfer. Our key innovation is the introduction of point-enhanced guidance, which provides flexible and reliable control over both spatial-level garment transfer and temporal-level video coherence. Specifically, we design a Point-Enhanced Transformer (PET) with two core components: Point-Enhanced Spatial Attention (PSA), which uses frame-cloth point alignments to precisely guide garment transfer, and Point-Enhanced Temporal Attention (PTA), which leverages frame-frame point correspondences to enhance temporal coherence and ensure smooth transitions across frames. Extensive experiments demonstrate that our PEMF-VTO outperforms state-of-the-art methods, generating more natural, coherent, and visually appealing try-on videos, particularly for challenging in-the-wild scenarios.
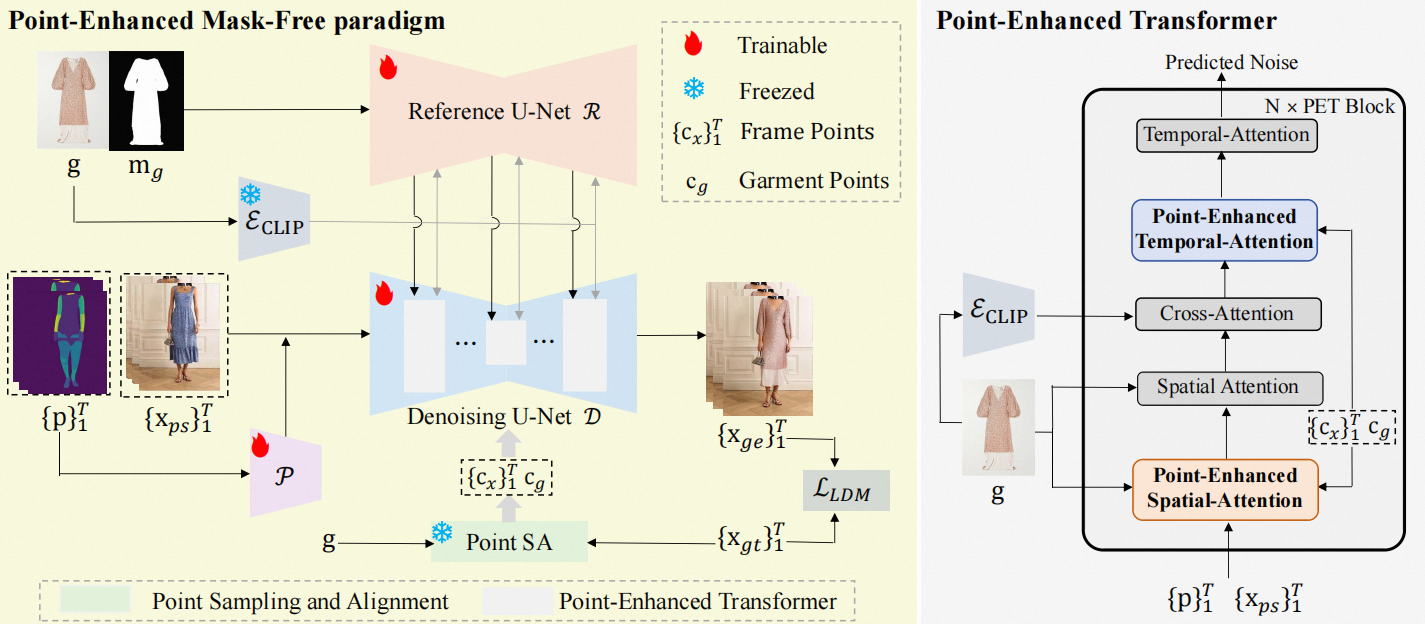
The pipeline of our PEMF-VTO framework. It leverages the paired pseudo-person data to train a mask-free model, thereby avoiding the loss of spatial-temporal information in the try-on area. Besides, based on the pre-acquired alignments between frame points and garment points, a novel point-enhanced transformer is proposed to respectively improve the garment transfer ability and coherence in the try-on area by the point-enhanced spatial attention and point-enhanced temporal attention modules.
The pipeline of the construction for point alignments between video frames and garment images.
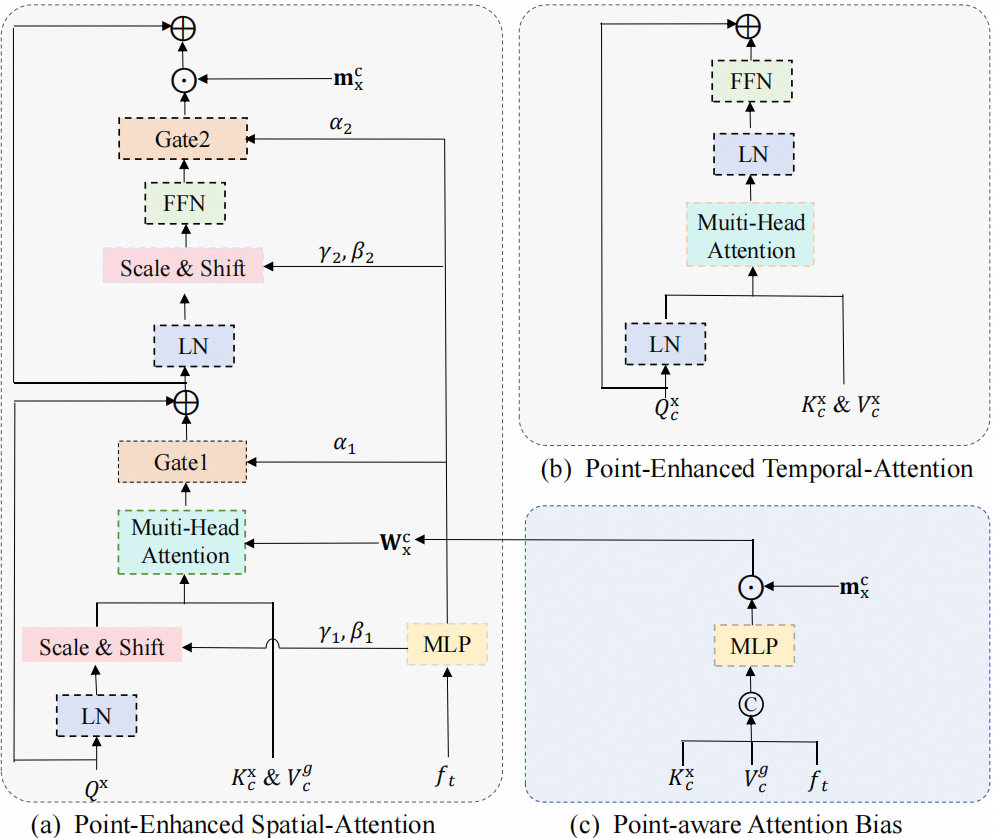
Point-enhanced Spatial Attention (PSA) and Point-enhanced Temporal (PTA) Attention modules.
@article{chang2024pemf,
author = {Chang, Tianyu and Chen, Xiaohao and Wei, zhichao and Zhang, Xuanpu and Chen, Qing-Guo and Luo, Weihua, Peipei Song and Yang, Xun},
title = {PEMF-VTO: Point-Enhanced Video Virtual Try-on via Mask-free Paradigm},
journal = {arXiv preprint arXiv:2412.03021},
year = {2024},
}